Learning Robust Optimal Policy from Strongly Correlated and Corrupted Observations
(ICML 2026, IEEE CDC 2024, CDC 2026, NeuRIPS 2025)


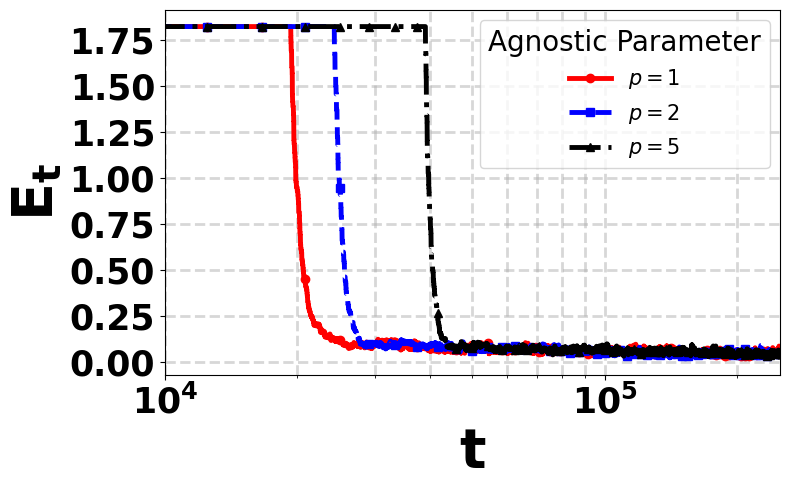

Recently, there has been a surge of interest in analyzing the non-asymptotic behavior of model-free reinforcement learning algorithms. However, the performance of such algorithms in non-ideal environments, such as in the presence of corrupted rewards, is poorly understood. Motivated by this gap, we investigate the robustness of the celebrated Q-learning algorithm to a strong-contamination attack model, where an adversary can arbitrarily perturb a small fraction of the observed rewards. We start by proving that such an attack can cause the vanilla Q-learning algorithm to incur arbitrarily large errors. We then develop novel, robust Q-learning algorithms that uses historical reward data to construct a robust empirical Bellman operator at each time step, without requiring knowledge of the true reward statistics. Finally, we prove finite-time convergence rates that matches known state-of-the-art bounds up to a small inevitable error term that scales with the adversarial corruption fraction. We further prove an information-theoretic lower bound, implying that dependence on the corruption fraction is inherent.
■ Corruption-Tolerant Asynchronous Q-Learning with Near-Optimal Rates [Accepted at the 43rd International Conference on Machine Learning ICML 2026]
■ Robust Asynchronous Q Learning under Corrupted Reward and State Corruption via Batching [Accepted at the 65th IEEE Conference on Decision and Control CDC 2026] [Paper ♾️] [Proceedings 📜] [Code 🖳] [Slides 📈]
■ Robust Q Learning under Corrupted Rewards [Accepted at the 63rd IEEE Conference on Decision and Control CDC 2024] [Paper ♾️] [Proceedings 📜] [Code 🖳] [Slides 📈]
■ Corruption-Tolerant Asynchronous Q-Learning with Near-Optimal Rates [Accepted at the 39th Annual conference on Neural Information Processing SystemsNeurIPS 2025-Reliable ML Workshop][Paper ♾️][Code 🖳][Slides 📈]
Mathematical Guarantees and Fundamental Limits of Policy Evaluation under Adversarial Influences and Markovian Data (AISTATS 2025)
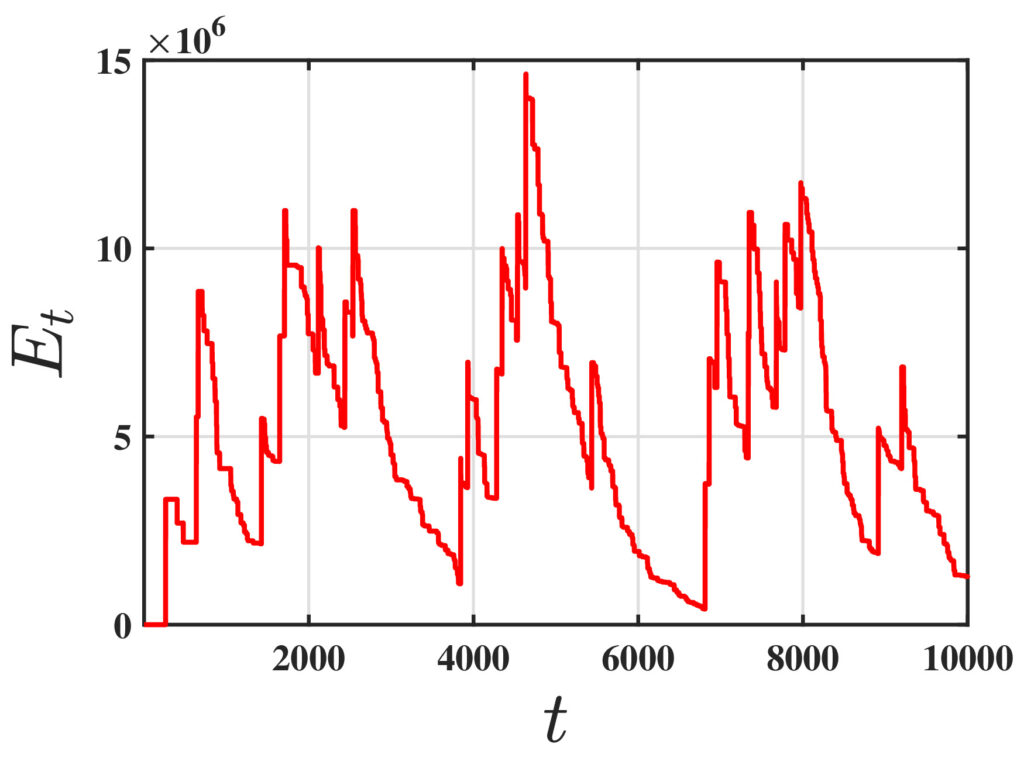
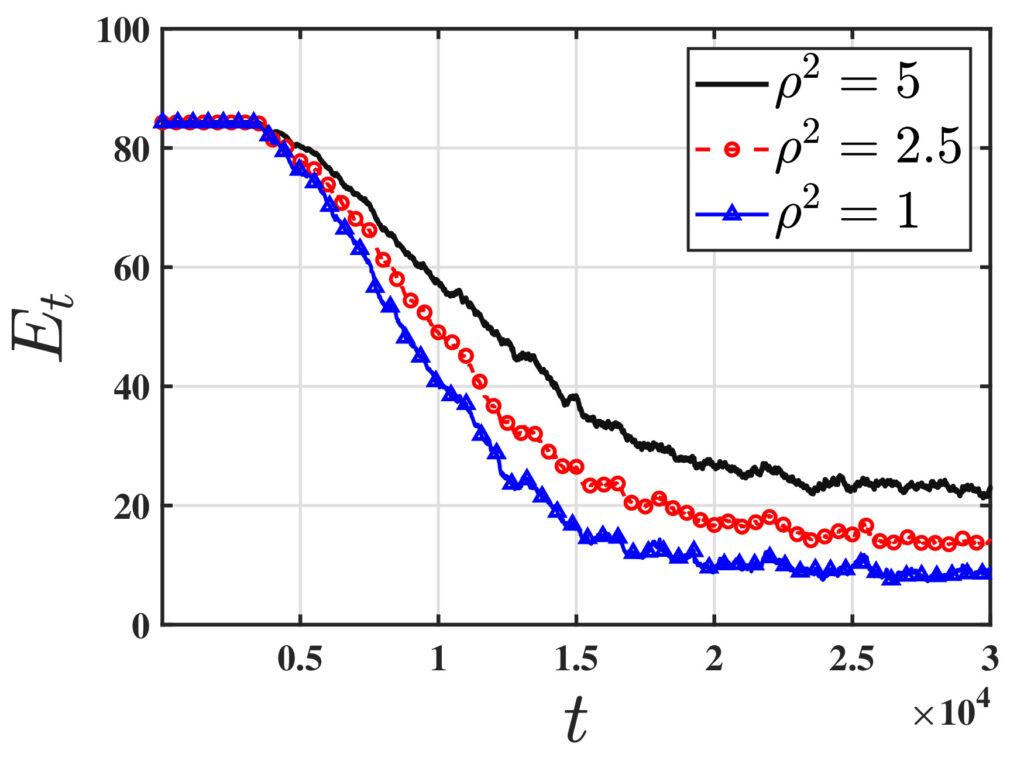
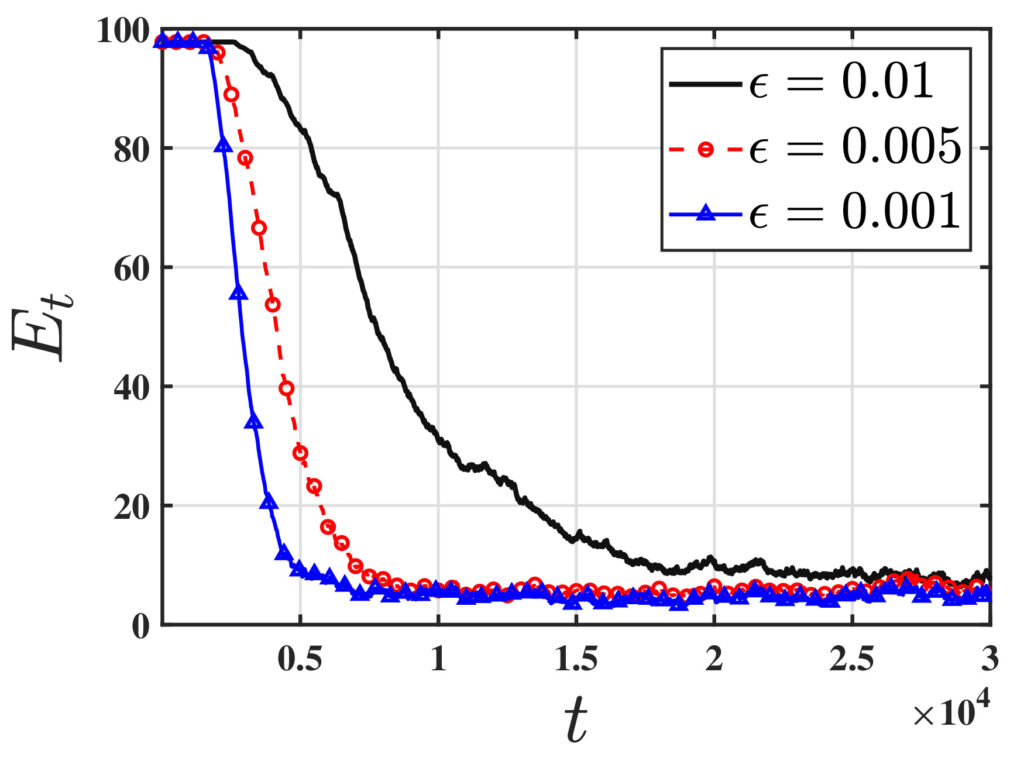
One of the fundamental challenges in reinforcement learning (RL) is policy evaluation, which involves estimating the value function—the long-term return—associated with a fixed policy. The well-known Temporal Difference (TD) learning algorithm addresses this problem, and recent research has provided finite-time convergence guarantees for TD and its variants. However, these guarantees typically rely on the assumption that reward observations are generated from a well-behaved (e.g., sub-Gaussian) true reward distribution. Recognizing that such assumptions may not hold in harsh, real-world environments, we revisit the policy evaluation problem through the lens of adversarial robustness. We then develop a novel algorithm called 𝚁𝚘𝚋𝚞𝚜𝚝-𝚃𝙳 and prove that its finite-time guarantees match that of 𝚅𝚊𝚗𝚒𝚕𝚕𝚊-𝚃𝙳 with linear function approximation up to a small O(ϵ) term that captures the effect of corruption. We complement this result with a minimax lower bound, revealing that such an additive corruption-induced term is unavoidable. To our knowledge, these results are the first of their kind in the context of adversarial robustness of stochastic approximation schemes driven by Markov noise.
■ Adversarially-Robust TD Learning with Markovian Data: Finite-Time Rates and Fundamental Limits [Accepted at the 28th International Conference on AI and Statistics AISTATS 2025] [Paper ♾️] [Proceedings 📜] [Code 🖳][Slides 📈]
{kind=link}
Provable Adversarial Robustness in Federated Multi-Agent Reinforcement Learning under Strong Communication Constraints (ACC 2026)





We consider a federated reinforcement learning setting involving M agents, all of whom interact with a common Markov Decision Process (MDP). The agents exchange information via a central server to learn the optimal value function. Our goal is to understand to what extent one can hope for collaborative sample-complexity speedups in such a setting, when a small fraction of the agents are adversarial and can act arbitrarily. To that end, we propose 𝚁𝚘𝚋𝚞𝚜𝚝 𝙵𝚎𝚍-𝚀, a federated Q-learning algorithm that blends ideas from both model-based and model-free RL, along with the median-of-means device from robust statistics. We prove that with high-probability, 𝚁𝚘𝚋𝚞𝚜𝚝 𝙵𝚎𝚍-𝚀 (i) guarantees exact convergence to the optimal value function in the limit of infinite samples, despite corruption, and (ii) enjoys near-optimal finite-time rates that benefit from collaboration. Perhaps surprisingly, our approach requires constant rounds of communication to achieve each of the above guarantees, a feature of independent interest in FL where communication is the major bottleneck.
■ 𝚁𝚘𝚋𝚞𝚜𝚝 𝙵𝚎𝚍-𝚀: Robust Federated Q-Learning with Almost No Communication. [Accepted at the 2026 American Control Conference ACC 2026] [Project]
■ 𝚅𝚁𝙳𝚀: Variance Reduced Q-Learning over time-varying Networks. [Accepted at the 2026 American Control Conference ACC 2026] [Project]
