Frozen Lake ❄️ Environment with Adversarial Rewards using our proposed Robust Q Learning Algorithm.
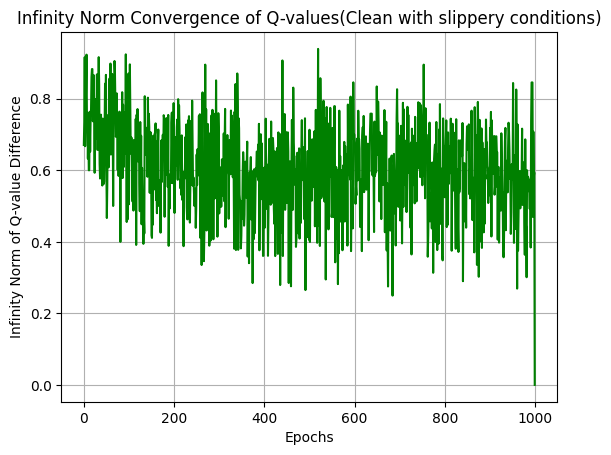
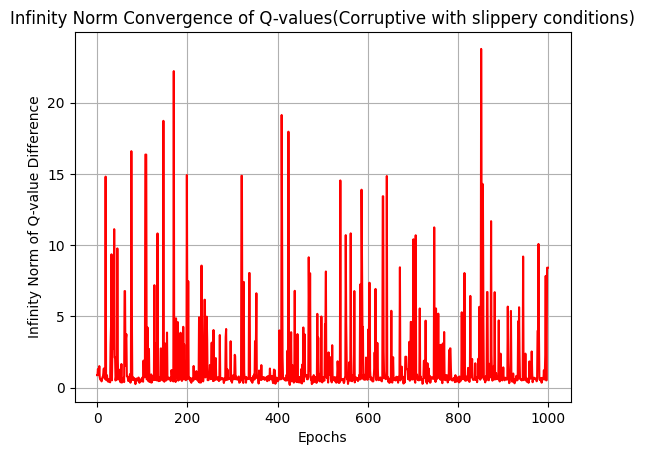
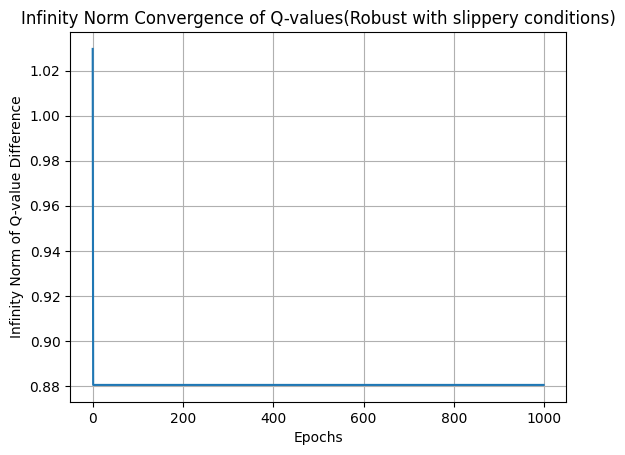
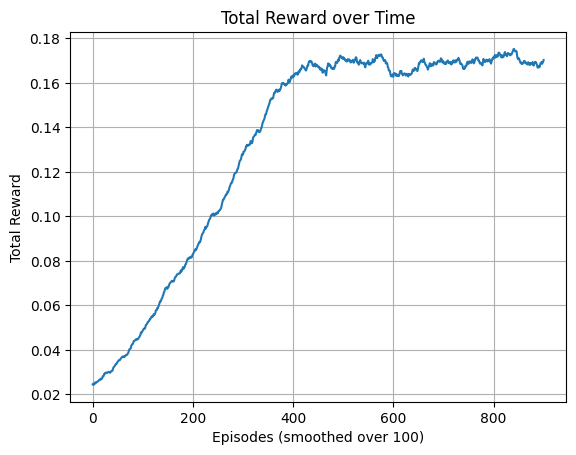
Our ε-Robust Q-Learning algorithm enhances traditional Q-learning in the Frozen Lake environment by integrating robust statistical methods to combat reward corruption. The algorithm navigates a grid of frozen tiles, aiming to reach a goal while avoiding holes, all while dealing with noise introduced by corrupted rewards. Instead of relying solely on raw rewards, it employs a univariate trimmed mean approach to estimate rewards, filtering out outliers and ensuring more stable learning. A threshold function limits the influence of extreme reward estimates, providing additional stability in Q-value updates. By using an ε-greedy strategy for action selection, the agent balances exploration and exploitation effectively, adapting over time to focus on learned strategies. This robust learning framework ensures the agent can reliably learn optimal policies even in the presence of adversarial conditions, making it particularly valuable for real-world applications where data integrity can be compromised. We have tested our algorithm in both slippery (this means, the player will move in the intended direction with a probability of 1/3 else will move in either perpendicular direction with an equal probability of 1/3 in both directions), and non-slippery conditions. Github Link